You are staring at your computer screen thinking how you are going to tell your ISO what you found. Thinking about how this single IDS alert might have been overlooked; how it might have been lost among the sea of alerts from the various security products deployed in your company. Your ISO tasked with you triaging a malware event and now you are ready to report back.
Triage Scenario
To fill in those readers who may not know what is going on you started out the meeting providing background information about the event. The practical provided the following abbreviated scenario (for the full scenario refer to the post Triage Practical – Malware Event – Prefetch $MFT IDS):
The ISO continued “I directed junior security guy to look at the IDS alerts that came in over the weekend. He said something very suspicious occurred early Saturday morning on August 15, 2015.” Then the ISO looked directly at you “I need you to look into whatever this activity is and report back what you find.” “Also, make sure you document the process you use since we are going to use it as a playbook for these types of security incidents going forward.”
Below are some of the initial questions you need to answer and report back to the ISO.
* Is this a confirmed malware security event or was the junior analyst mistaken?
* What type of malware is involved?
* What potential risk does the malware pose to your organization?
* Based on the available information, what do you think occurred on the system to cause the malware event in the first place?
Information Available
Despite the wealth of information available to you within an enterprise, only a subset of data was provided for you to use while triaging this malware event. The following artifacts were made available:
* IDS alerts for the time frame in question (you need to replay the provide pcap to generate the IDS alerts. pcap was not provided for you to use during triage and was only made available to enable you to generate the IDS alerts in question)
* Prefetch files from the system in question (inside the Prefetch.ad1 file)
* File system metadata from the system in question (the Master File Table is provided for this practical)
Information Storage Location within an Enterprise
Each enterprise’s network is different and each one offers different information for triaging. As such, it is not possible to outline all the possible locations where this information could be located in enterprises. However, it is possible to highlight common areas where this information can be found. To those reading this post whose environments do not reflect the locations I mention then you can evaluate your network environment for a similar system containing similar information or better prepare your network environment by making sure this information starts being collected in systems.
* IDS alerts within an enterprise can be stored on the IDS/IPS sensors themselves or centrally located through a management console and/or logging system (i.e. SIEM)
* Prefetch files within an enterprise can be located on the potentially infected system
* File system metadata within an enterprise can be located on the potentially infected system
Collecting the Information from the Storage Locations
Knowing where information is available within an enterprise is only part of the equation. It is necessary to collect the information so it can be used for triaging. Similar to all the differences between enterprises’ networks, how information is collected varies from one organization to the next. Below are a few suggestions for how the information outlined above can be collected.
* IDS alerts don’t have to be collected. They only need to be made available so they can be reviewed. Typically this is accomplished through a management console or security monitoring dashboard.
* Prefetch files are stored on the potentially infected system. The collection of this artifact can be done by either pulling the files off remotely or locally. Remote options include an enterprise forensic tools such as F-Response, Encase Enterprise, or GRR Rapid Response, triage scripts such as Tr3Secure collection script, or by using the admin share since Prefetch files are not locked files. Local options can use the same options.
* File system metadata is very similar to prefetch files because the same collection methods work for collecting it. The one exception is the NTFS Master File Table ($MFT) can’t be pulled off by using the admin share.
Potential DFIR Tools to Use
The last part of the equation is what tools one should use to examine the information that is collected. The tools I’m outlining below are the ones I used to complete the practical.
*
Security Onion to generate the IDS alerts
*
Winprefetchview to parse and examine the prefetch files
*
MFT2CSV to parse and examine the $MFT file
Others’ Approaches to Triaging the Malware Event
Before I dive into how I triaged the malware event I wanted to share the approaches used by others to tackle the same malware event. I find it helpful to see different perspectives and techniques tried to solve the same issue. I also wanted to thank those who took the time to do this so others could benefit from what you share.
Matt Gregory shared his analysis on his blog My Random Thoughts on InfoSec. Matt did a great job outlining not only what he found but by explaining how he did it and what tools he used. I highly recommend taking the time to read through his analysis and the thought process he used to approach this malware event.
An anonymous person (at least anonymous to me since I couldn’t locate their name) posted their analysis on a newly created blog called Forensic Insights. Their post goes into detail on analyzing the packet capture including what was transmitted to the remote device.
Partial Malware Event Triage Workflow
The diagram below outlines the jIIr workflow for confirming malicious code events. The workflow is a modified version of the Securosis Malware Analysis Quant. I modified Securosis process to make it easier to use for security event analysis.
Detection: the malicious code event is detected. Detection can be a result of technologies alerting on it or a person reporting it. The workflow starts in response to a potential event being detected and reported.
Triage: the detected malicious code event is triaged to determine if it is a false positive or a real security event.
Compromised: after the event is triaged the first decision point is to decide if the machine could potentially be compromised. If the event is a false positive or one showing the machine couldn’t be infected then the workflow is exited and returns back to monitoring the network. If the event is confirmed or there is a strong indication it is real then the workflow continues to identify the malware.
Malware Identified: the malware is identified two ways. The first way is identifying what the malware is including its purpose and characteristics using available information. The second way is identifying and obtaining the malware sample from the actual system to further identify the malware and its characteristics.
Root Cause Analysis: a quick root cause analysis is performed to determine how the machine was compromised and to identify indicators to use for scoping the incident. This root cause analysis does not call for a deep dive analysis taking hours and/or days but one only taking minutes.
Quarantine: the machine is finally quarantined from the network it is connected to. This workflow takes into account performing analysis remotely so disconnecting the machine from the network is done at a later point in the workflow. If the machine is initially disconnected after detection then analysis cannot be performed until someone either physically visits the machine or ships the machine to you. If an organization’s security monitoring and incident response capability is not mature enough to perform root cause analysis in minutes and analysis live over the wire then the Quarantine activity should occur once the decision is made about the machine being compromised.
Triage Analysis Solution
To triage the malware event outlined in the scenario does not require one to use all of the supplied information. The triage process could had started with either the IDS alert the junior security analyst saw or the prefetch files from system in question to see what program executed early Saturday morning on August 15, 2015. For completeness, my analysis touches on each data source and the information it contains. As a result, I started with the IDS signature to ensure I included it in my analysis.
IDS alerts
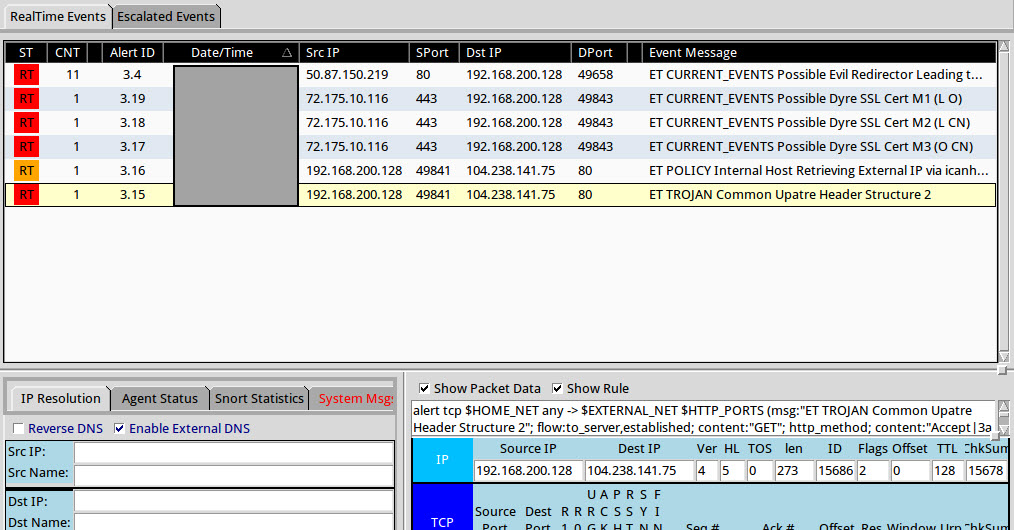
The screenshot below shows the IDS signatures that triggered by replaying the provided malware-event.pcap file in Security Onion. I highlighted the alert of interest.
The IDS alert by itself provides a wealth of information. The Emerging Threats (ET) signature that fired was "ET TROJAN HawkEye Keylogger FTP" and this occurred when the machine in question (192.168.200.128) made a connection to the IP address 107.180.21.230 on the FTP destination port 21. To determine if the alert is a false positive it’s necessary to explore the signature (if available) and the packet responsible for triggering it. The screenshot below shows the signature in question:
The signature is looking for a system on the $HOME_NET going to an external system on the FTP port 21 and the system has to initiate the connection (as reflected by flow:established,to_server). The packet needs to contain the string “STOR HAWKEye_”. The packet that triggered this signature meets all of these requirements. The system connected to an external IP address on port 21 and the picture below shows the data in the packet contained the string of interest.

Based on the network traffic and the packet data the IDS alert is not a false positive. I performed Internet research to obtain more context about the malware event. A simple Google search on HawkEye Keylogger produces numerous hits. From You Tube videos showing how to use it to forums posting cracked versions to various articles discussing it. One article is TrendMicro’s paper titled Piercing the HawkEye: Nigerian Cybercriminals Use a Simple Keylogger to Prey on SMBs Worldwide and just the pictures in the paper provide additional context (remember during triage you won’t have time to read 34 page paper.) The keylogger is easily customizable since it has a builder and it can delivery logs through SMTP or FTP. Additional functionality includes: stealing clipboard data, taking screenshots, downloading and executing other files, and collecting system information.
Research on the destination IP address shows the AS is GODADDY and numerous domain names map back to the address.
Prefetch files
When I review programs executing on a system I tend to keep the high level indicators below in mind. Over the years, these indicators have enabled me to quickly identify malicious programs that are or were on a system.
- Programs executing from temporary or cache folders
- Programs executing from user profiles (AppData, Roaming, Local, etc)
- Programs executing from C:\ProgramData or All Users profile
- Programs executing from C:\RECYCLER
- Programs stored as Alternate Data Streams (i.e. C:\Windows\System32:svchost.exe)
- Programs with random and unusual file names
- Windows programs located in wrong folders (i.e. C:\Windows\svchost.exe)
- Other activity on the system around suspicious files
The collected prefetch files were parsed with Winprefetchview and I initially sorted by process path. I reviewed the parsed prefetch files using my general indicators and I found the suspicious program highlighted in red.
The program in question is suspicious for two reasons. First, the program executed from the temporarily Internet files folder. The second reason and more important one was the name of the program, which was OVERDUE INVOICE DOCUMENTS FOR PAYMENT 082015[1].EXE (%20 is the encoding for a space). The name resembles a program trying to be disguised as a document. This is a social engineering technique used with phishing emails. To gain more context around the suspicious program I then sorted by the Last Run time to see what else was executing around this time.
The OVERDUE INVOICE DOCUMENTS FOR PAYMENT 082015[1].EXE program executed on 8/15/15 at 5:33:55 AM UTC, which matches up to the time frame the junior security analyst mentioned. The file had a MD5 hash of ea0995d9e52a436e80b9ad341ff4ee62. This hash was used to confirm the file was malicious as reflected in an available VirusTotal report. Shortly thereafter another executable ran named VBC.exe but the process path was not reflected in the files referenced in the prefetch file itself. The other prefetch files did not show anything else I could easily tie to the malware event.
File System Metadata
At this point the IDS alert revealed the system in question had network activity related to the HawkEye Keylogger. The prefetch files revealed a suspicious program named OVERDUE INVOICE DOCUMENTS FOR PAYMENT 082015[1].EXE and it executed on 8/15/15 at 5:33:55 AM UTC. The next step in the triage process is to examine the file system metadata to identify any other malicious software on the system and to try to identify the initial infection vector. I reviewed the metadata in a timeline to make it easier to see the activity for the time of interest.
For this practical I leveraged the MFT2CSV program in the configuration below to generate a timeline. However, an effective technique - but not free - is using the home plate feature in Encase Enterprise against a remote system. This enables you to see all files and folders while being able to sort different ways. The Encase Enterprise method is not as comprehensive as a $MFT timeline but works well for triaging.
In the timeline I went to the time of interest, which was 8/15/15 at 5:33:55 AM UTC. I then proceeded forward in time to identify any other suspicious files. A few files were created within seconds of the OVERDUE INVOICE DOCUMENTS FOR PAYMENT 082015[1].EXE program executing. The files’ hashes will need to be used to determine more information about them since I am unable to view them.
The timeline then shows the VBC.EXE program executing followed by activity associated with a user surfing the Internet.
The timeline was reviewed for about a minute after the suspicious program executed and nothing else jumps out. The next step is go back to 8/15/15 at 5:33:55 AM UTC in the timeline to see what proceeded this event. There was more activity related to the user surfing the Internet as shown below.

I kept working my way through the web browsing files to find something to confirm what the user was actually doing. I worked my way through Yahoo cookies and cache web pages containing the word “messages”. There was nothing definite so I continued going back in time. I worked my way back to around 5:30 AM UTC where cookies for Yahoo web mail were created. This activity was three minutes prior to the infection; three minutes is a long time. At this point additional information is needed to definitely answer how the system became infected in the first place. At least I know that it came from the Internet using a web browser. note: in the scenario the pcap file was meant for IDS alerts only so I couldn’t use it to answer the vector question.
Researching Suspicious Files
The analysis is not complete without researching the suspicious files discovered through triage. I performed additional research on the file OVERDUE INVOICE DOCUMENTS FOR PAYMENT 082015[1].EXE using its MD5 hash ea0995d9e52a436e80b9ad341ff4ee62. I went back to its VirusTotal report and noticed there didn’t appear to be a common name in the various security product detections. However, there were unique detection names I used to conduct additional research. Microsoft’s detection name was TrojanSpy:MSIL/Golroted.B and their report said the malware “tries to gather information stored on your PC”. A Google search of the hash also located a Malwr sandbox report for the file. The report didn’t shed any light on the other files I found in the timeline.
The VBC.EXE file was no longer on the system preventing me from performing additional research on this file. The pid.txt and pidloc.txt files’ hashes were associated with a Hybrid Analysis report for a sample with the MD5 hash 242e9869ec694c6265afa533cfdf3e08. The report had a few interesting things. The sample also dropped the pid.txt and pidloc.txt files as well as executing the REGSVCS.EXE as a child process. This is the same behavior I saw in the file system metadata and prefetch files. The report provided a few other nuggets such as the sample tries to dump Web browser and Outlook stored passwords.
Triage Analysis Wrap-up
The triage process did confirm the system was infected with malicious code. The infection was a result of the user doing something on the Internet and additional information is needed to confirm what occurred on the system for it to become infected in the first place. The risk to the organization is the malicious code tries to capture and exfiltrate information from the system including passwords. The next step would be to escalate the malware event to the incident response process so a deeper analysis can be done to answer more questions. Questions such as what data was potentially exposed, what did the user do to contribute to the infection, was the attack random or targeted, and what type of response should be done.
 In the Fall I was staring out my back window seeing my yard covered in orange leaves. This sight is one I see each year and I have always viewed as my yearly chore. The chore of cleaning up the leaves that have fallen from the trees. At times I would see some joy the leaves would bring as my kids would play in them but mostly I viewed the leaves with disdain. Knowing I would be spending hours upon hours cleaning it up. I came to accept this yearly chore as something that doesn’t change since it came with the territory of owning a property with trees. This was until I became more knowledgeable about a subject and this knowledge changed my perspective on how I see these leaves.
In the Fall I was staring out my back window seeing my yard covered in orange leaves. This sight is one I see each year and I have always viewed as my yearly chore. The chore of cleaning up the leaves that have fallen from the trees. At times I would see some joy the leaves would bring as my kids would play in them but mostly I viewed the leaves with disdain. Knowing I would be spending hours upon hours cleaning it up. I came to accept this yearly chore as something that doesn’t change since it came with the territory of owning a property with trees. This was until I became more knowledgeable about a subject and this knowledge changed my perspective on how I see these leaves.